This article shows how to use the GetWordForm command in a pipeline to extract data from MS Word documents containing form field data, ie “content controls”.
Introduction
A single MS word document (.docx) or a zip file containing many word documents may be loaded. Only .docx format files are supported (2007 and later). The GetWordForm command attempts to extract 1 record for each document. A zip file containing 50 .docx files should extract a table with 50 records. Fields present in some documents but not others are simply added to the extracted table.
Activate Developer toolbar
This is not a tutorial on how to create MS Word Forms but one hint if you want to see the properties of the form field controls, is to activate the Developer toolbar in word.
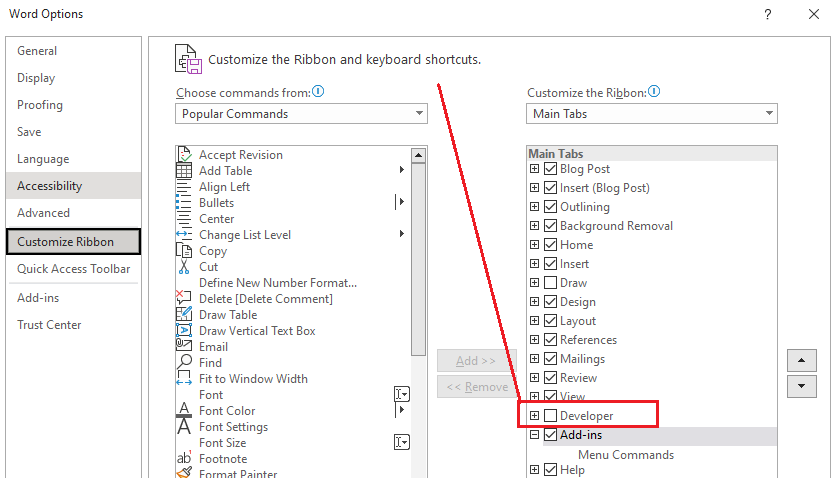
Then you can choose any content control field in the word document and press the Properties button on the Developer toolbar to see the detailed properties of the control, such as the Tag and Title. Tag and Title are the most important fields with regards to setting up the pipeline because they become the column names of the extracted data (default is Tag).
Pipeline example
An example of a pipeline to load data from MS Word Forms:
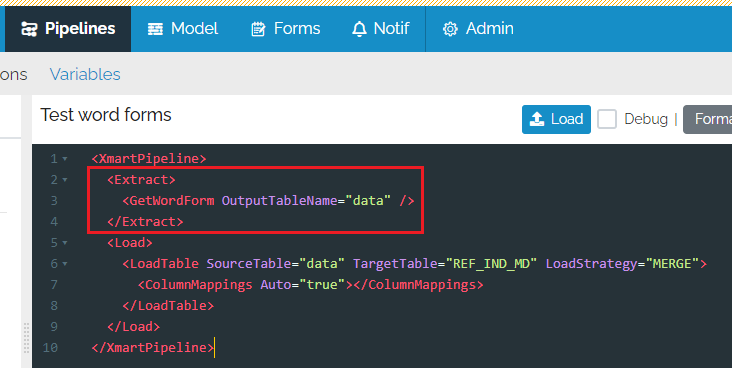
When the GetWordForm step has completed, the name of the in-memory table after extraction will be “data”, there will be 1 record per word document and the column names will match the Tag property of the content controls. To use the Title property instead set the ColumnNamesFrom property to “Title”.
With this pipeline the data loader can either upload
- A single MS Word document (which would create a table with 1 record)
- A zip file of MS Word documents
Example of a zip file. Files can be nested in folders inside the zip.
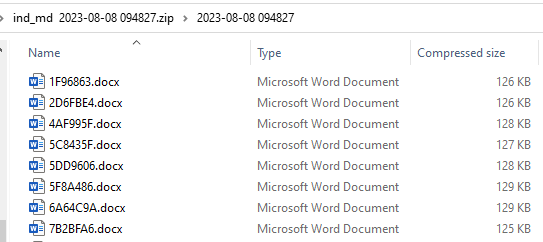
The name of each word file is also extracted as a data colum. This can be useful if the MS Word filename itself contains important data.
View data with debug mode
Use the Test button and debug mode to get an idea of how the data is extracted. Note that this can be done even before a target table has been created. You can just choose any existing table as a “dummy” target table. Test batches are not committable unless the pipeline is first published so there is no danger in accidentally modifying the dummy target table.
Pressing the Test button will open a load screen where you can drop a zip or single MS Word file.
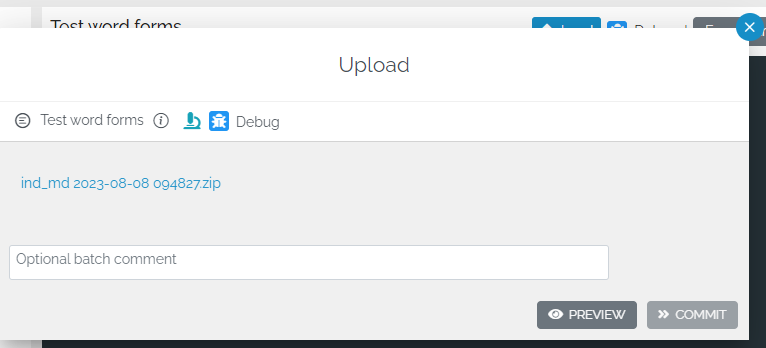
Click preview, wait a while, and then select the xml line with GetWordForm. You should see the extracted data on the right. Use the column chooser to hide/show selected columns. Note that the first column, MSWORD_FILE_NAME, contains the name of the file.
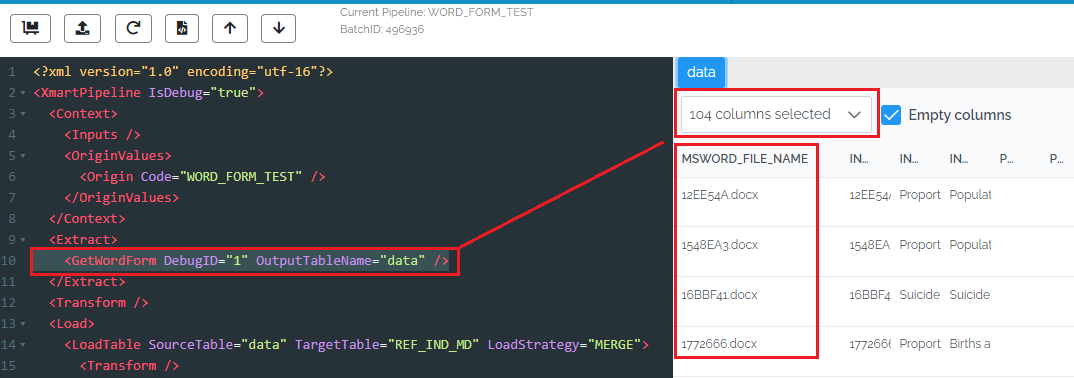
At this point there is an in-memory table in the pipeline called “data” containing the data from the MS Word Files. It can be processed normally as for any other data.