Data Modelling Basics
Getting started
If you imagine you were going to build a warehouse for storing products to ship to customers, there are various questions you would ask yourself:
- What products am I going to store?
- How am I going to arrange the products? Do I need new shelves or do the products belong on other existing shelves?
- How am I going to organise my products on the shelves ?
- How am I going to split my shelves into sections to hold the products?
- How am I going to be able to find the products?
- Do I have products that are connected in some way ?
- Do I need a new warehouse or can I use one that already exists?
You can think about marts in a similar way. You need to ask the same sort of questions
- What data am I going to store?
- How am I going to arrange the data? Do I need new tables or does the data belong on other existing tables?
- How am I going to organise my data in the tables?
- How am I going to be able to find the data?
- Do I have data that is connected in some way ?
- Do I need a new mart or can I use one that already exists?
If you need a new set of tables then you will need to create a good model for it.
What is a data model?
A data model consists of several parts
- Location (Mart)
- Tables
- Fields in the Tables
- Fact and reference data
- How the Tables relate to each other
Tables
What is a table?
Like an Excel tab, a table is a set of data stored in rows and columns.
In an Excel tab, the columns run across the top and are referred to be letters and the rows run down the side and are referred to by numbers.
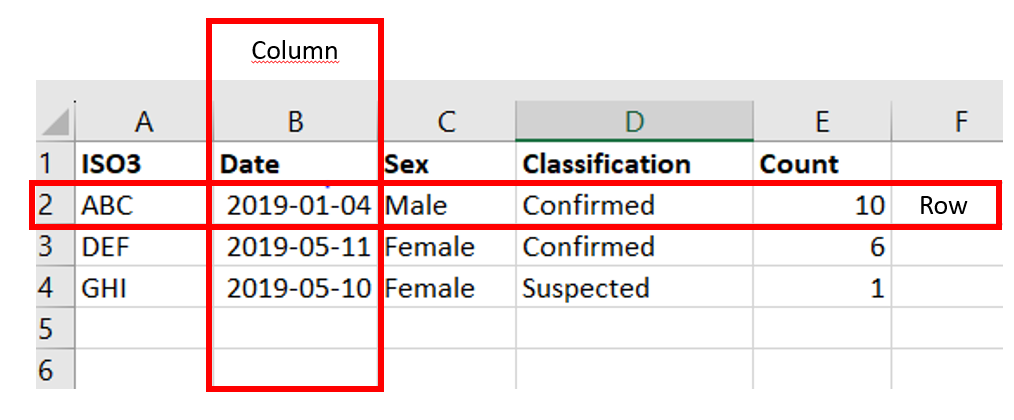
A table is the same where the columns have headings and are across the top and the data has rows and goes down the side.
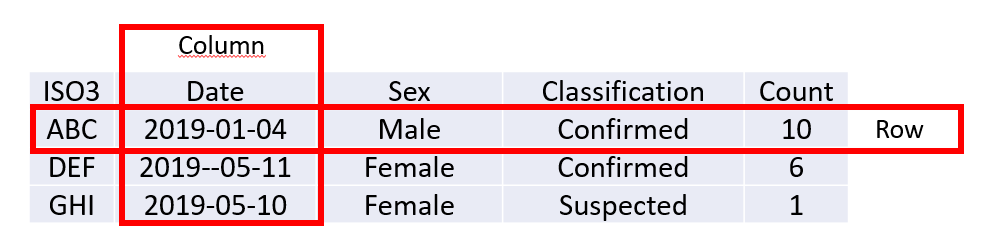
Like Excel tabs and cells which can reference each other, tables and columns can reference each other.
Unlike Excel columns, each table can have business primary keys, and each table column must have a data type reflecting the data which is going to be stored.
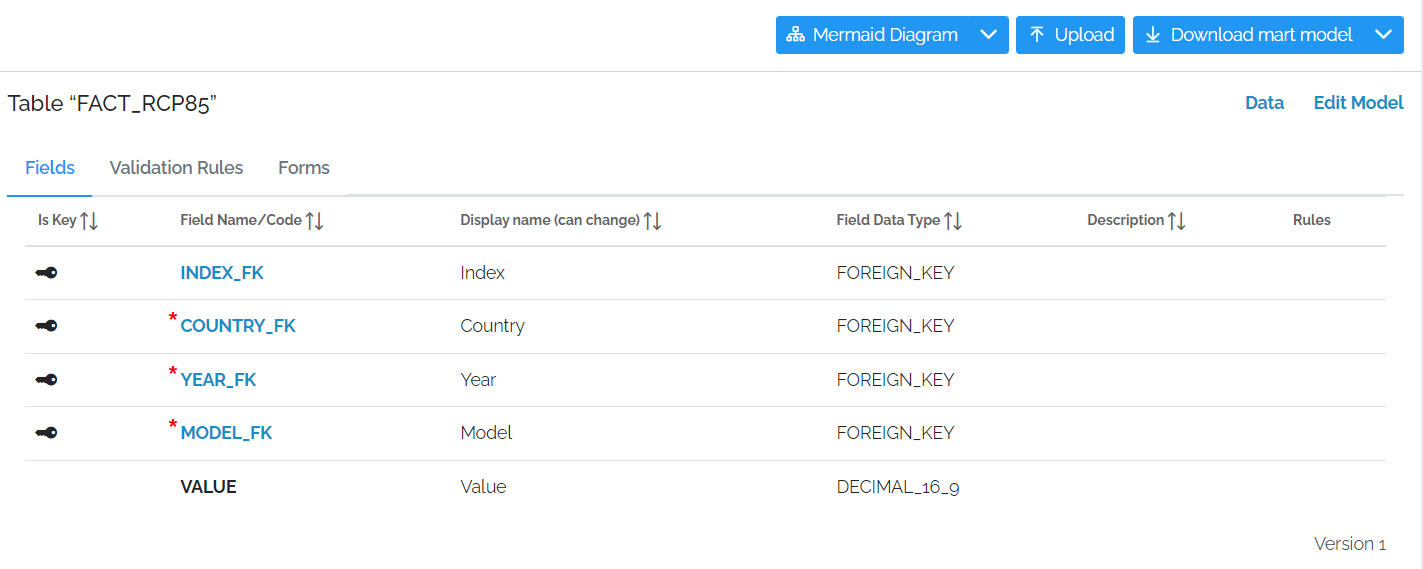
Business Primary Keys (BPKs)
Business Primary Keys are the fields in a table which together uniquely identify each record in the table. This allows the system to distinguish previously loaded data from new data and provide the data loader with a report of which records are new, updated or unchanged. They also improve data both integrity and performance speed.
The word “business” is used to indicate these are fields in the “business” domain, as opposed to internal system primary keys (like xMart’s Sys_PK and Sys_ID fields).
Business primary keys are not required in xMart but they are strongly recommended and should be used whenever possible. At least one BPK must be set to Mandatory; the others may be nullable. In xMart null BPKs are treated and compared like values.
BPKs are displayed as a Key icon in the Is Key field. A red star next to the field code indicates that it is mandatory
What are data types?
In Excel, the user can suggest a column or set of cells to have a type by formatting the cell
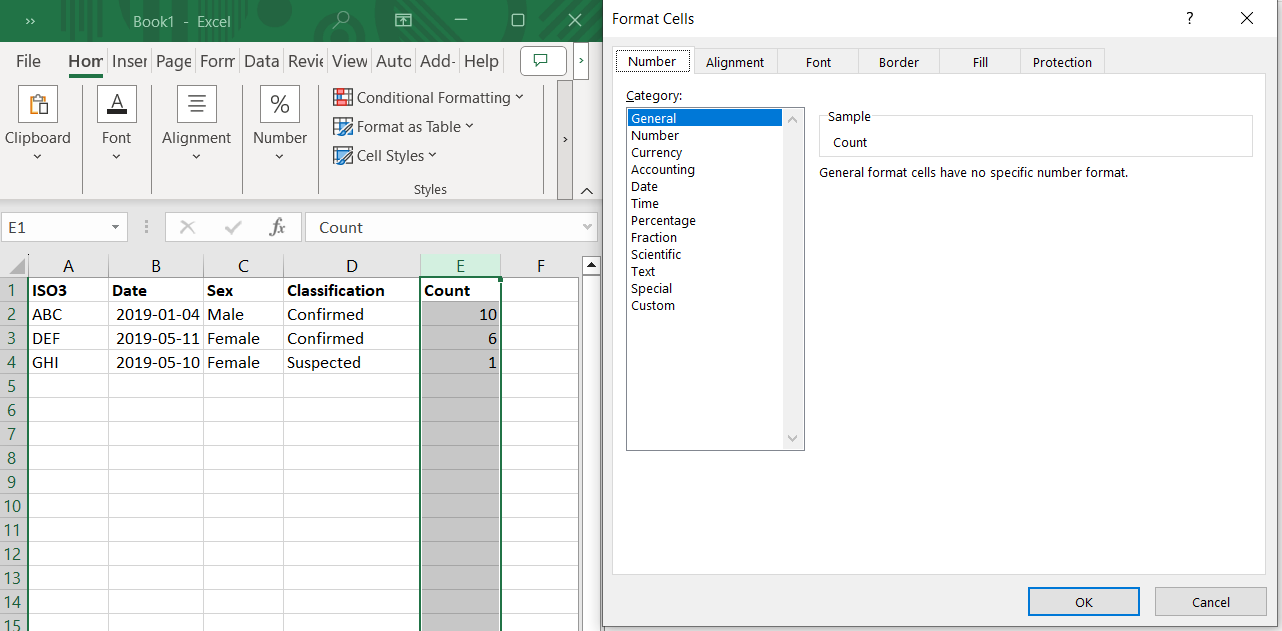
There are various data types available which vary from system to system. They are mostly the same but sometimes have different names.
In xMart, there are the following data types
Integer data types
| Data Type | Storage |
|---|---|
| BIG_INTEGER | Whole number from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
| INTEGER | Whole number from -2,147,483,648 to 2,147,483,647 |
Decimal data types
| Data Type | Storage |
|---|---|
| DECIMAL_16_9 | A decimal datatype limited to 16 digits total: 7 digits to the left of the decimal point and 9 to the right. |
| DECIMAL_28_14 | A decimal datatype limited to 28 digits total: 14 digits to the left of the decimal point and 14 to the right. |
| DECIMAL_28_9 | A decimal datatype limited to 28 digits total: 19 digits to the left of the decimal point and 9 to the right. |
| PERCENT | Decimal percent data type, from -1000 to 1000. Input string format expected to end with ‘’%’’ character |
String data types
The string types in xMart are unicode (extended) character strings (i.e. support Chinese, Russian etc.) of the length specified.
| Data Type | Storage |
|---|---|
| TEXT_2 | 2 unicode characters |
| TEXT_3 | 3 unicode characters |
| TEXT_10 | 10 unicode characters |
| TEXT_50 | 50 unicode characters |
| TEXT_450 | 450 unicode characters |
| TEXT_4000 | 4000 unicode characters |
| TEXT_MAX | Up to 2GB of Text but can be slow when filtered |
Data and Time data types
| Data Type | Storage |
|---|---|
| DATE | Date values including year, month and day. No time information. |
| DATE_TIME | Date-time values including year, month, day and also time values to sub-second precision. |
| MONTH | 1 or 2 digit month values such as 3 (March) or 10 (October) |
| YEAR | Full-digit year values, such as ‘2003’ |
Other data types
| Data Type | Storage |
|---|---|
| BOOLEAN | Stored as 1 or 0 but data can be provided using various common synonyms such as True/False, T/F, Yes/No, Y/N. |
| GUID | 36-character value that is globally unique across tables, databases, and servers. |
| MEDIA | Media type for binary data like pictures/files. For better display, a field with code MIMETYPE will be used if available. We don’t recommend storing these types of files because the retrieval can be slow |
| XML | Valid XML |
| FOREIGN_KEY | Foreign key to another table |
| COMPUTED TYPE | You may use SQL expressions to calculate values and pull Foreign Keys from other tables. See the COMPUTED field type article for more information. |
Foreign Keys
A Foreign Key is used to join tables together. It makes sure that any value put into a field (the foreign key field) exists in a field in another table (the foreign key table). This is useful for checking and enforcing that loaded data is valid. For example, if someone loads an invalid country code, the load procedure won’t accept it and will flag it as an error.
Here is an example of a Foreign Key being used to connect Fact data with Reference data. The value “MALE” in the column Sex of the fact table must be found in the Code column of the Gender reference table. The value “Confirmed” in the column Classification of the fact table must be found in the Code column of the Classification reference table.
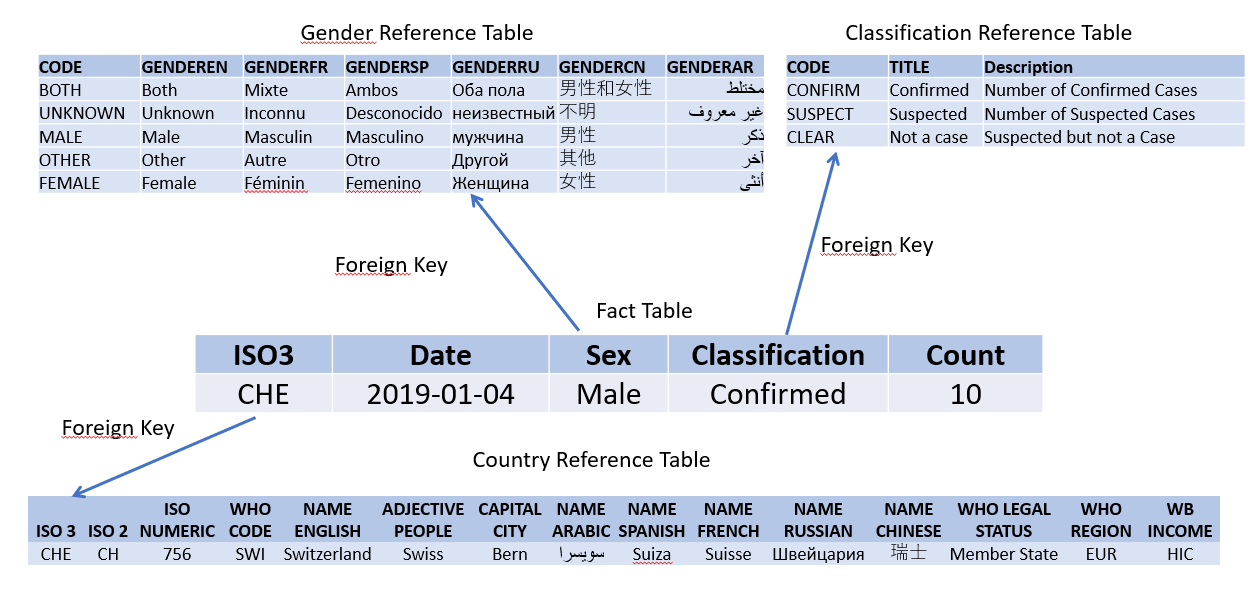
The Row Title/Code field
Why is the Code column of the reference table the field that needs to be matched?
It can actually be any column. You define which column should be matched by designating which field in the reference table is the “row title”. The values in the “row title” must be unique in the foreign key table. You can think of the row title field also as a code field, because it shouldn’t casually be changed. Only one single field in a foreign key table can be designated as the row title field.
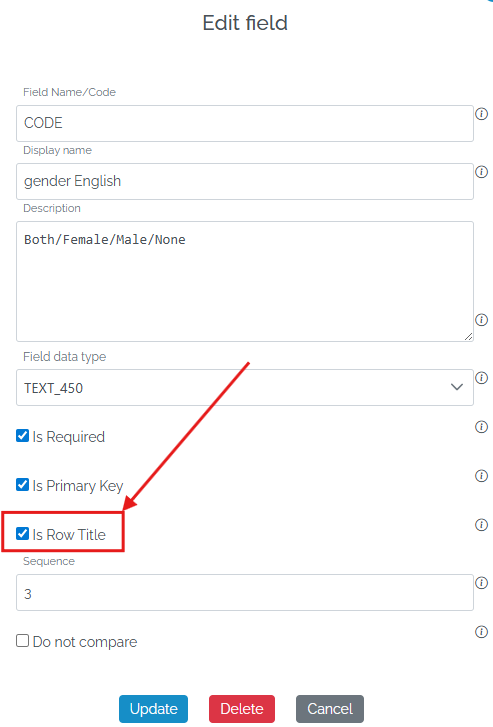
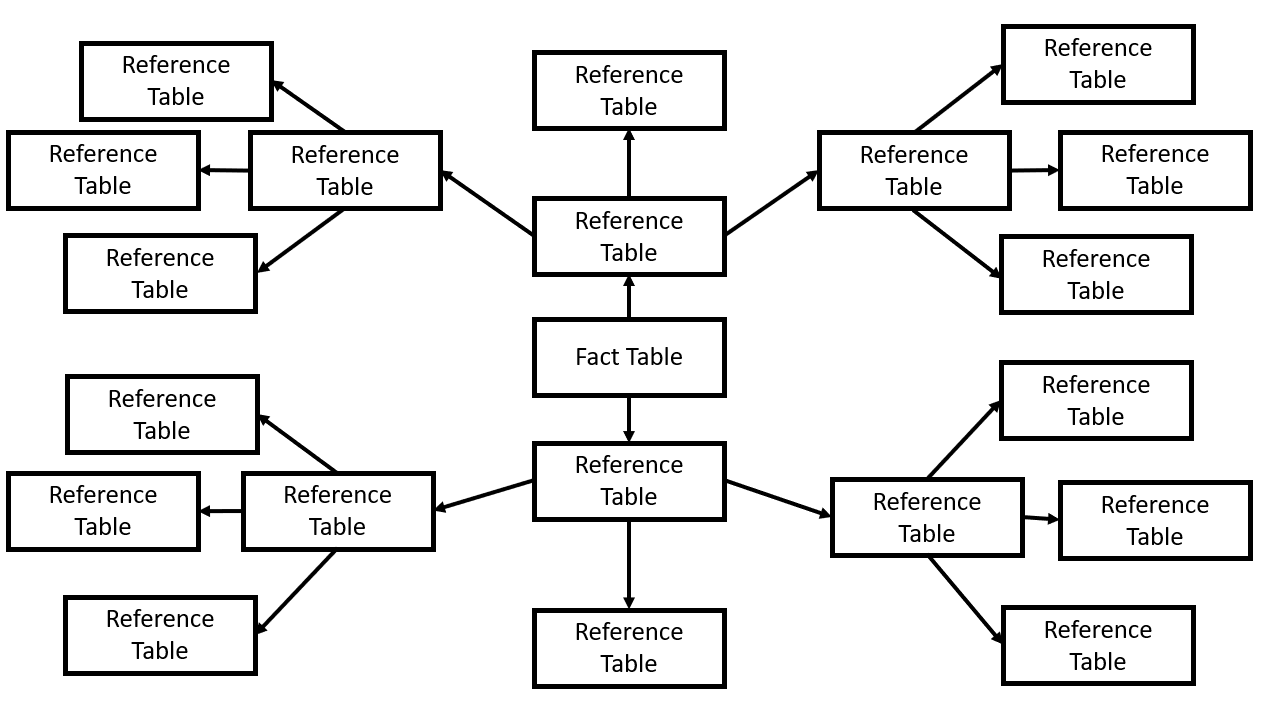
Star Schema
The above arrangement is known as a Star schema because it can be represented in a diagram the Fact table sits in the middle and the Reference tables sitting all around it connected by lines so it would look like an star.
Snowflake Schema
You can have Reference tables which have Foreign Keys as well. So for example, it I have a Reference table of countries and a Reference table of Country Capital Cities, I can join my Fact table to the capital cities be going through the Country Reference table.
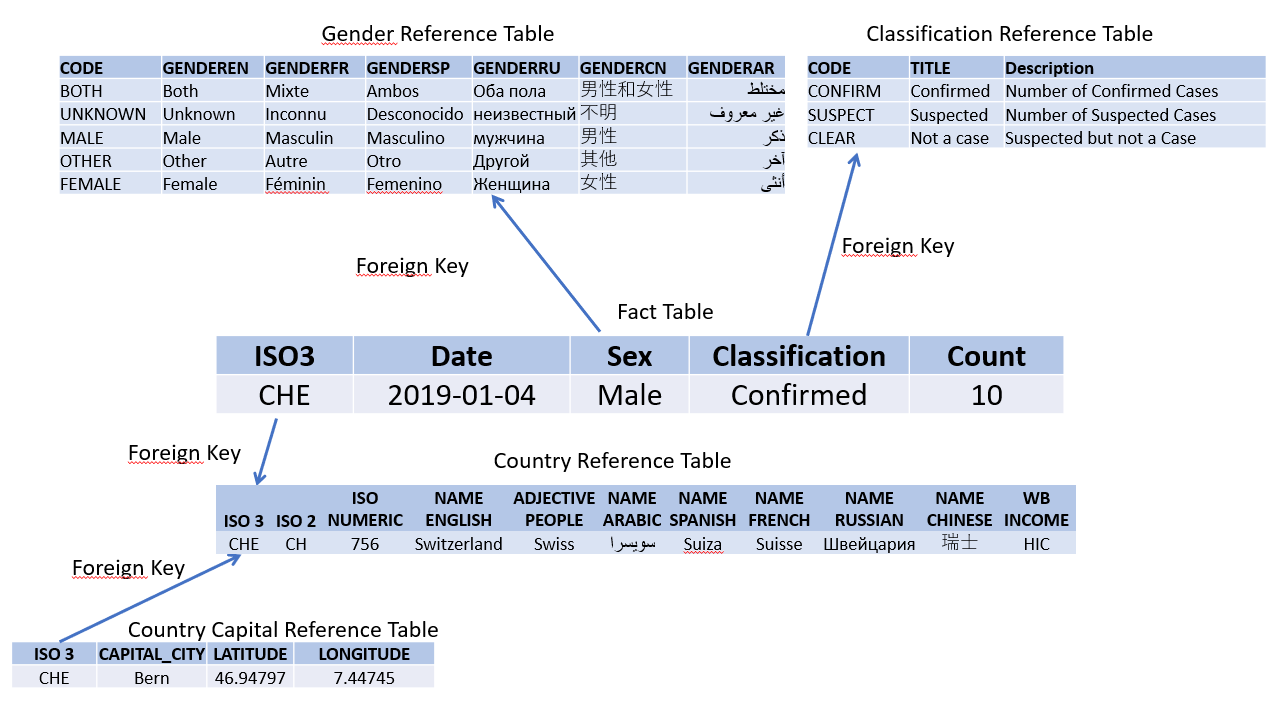
This is known as a Snowflake Schema because the Fact table sits in the middle and the lines come off it and then other lines come off them so the lines resemble a snowflake
Data Cleansing
Apart from joining tables, Foreign Keys also checks the data entered for valid values so are a form of data cleansing.
There are various reasons why data may be rejected as invalid
| Possible reason | Resolution |
|---|---|
| There is a value which is completely invalid like an ISO3 Code of “ZZZ” | This is invalid so they will need to correct it |
| The value is in another language or is an alternative spelling (for example “Suisse” instead of “Switzerland”) | It’s valid but in a different language. Use a different column for the lookup or use a Synonym table |
| There is a spelling mistake on the data source (for example “Siwtzerland” instead of “Switzerland”) | If the data comes from a user via Excel or CSV then it is best to correct it at source. However, it is not always possible to do this if the data comes from an extarnal source like another agengy. In which case, it is best to use a synonym table |
Synonym tables
A Synonym table is a normal table that you create which can be used to convert a diversity of incoming freetext values to a single standardized values.

Types of data
There are two main types of data, non tabular data, such as documents, images and blocks of JSON or XML, and tabular data. Tabular data can be though of as the sort of data you can put into an Excel spreadsheet with rows and columns. xMart is designed to store and work with tabular data.
Types of tabular data
There are several ways to think of tabular data, depending upon how it is used.
Fact and Reference data
Here is a typical Excel spreadsheet with data in it.
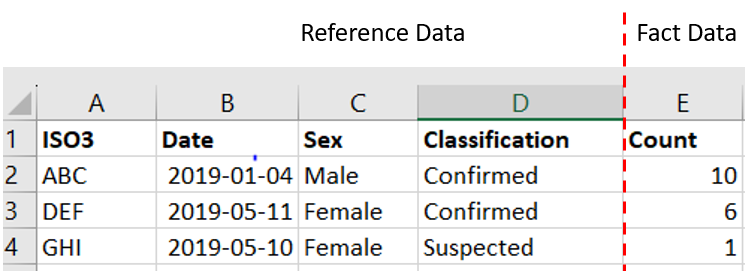
You would expect a report on this data to be filtered by ISO3, Date, Sex and Classification. The numerical Count field, on the other hand, would be expected to be compared, summed, averaged etc.
The Count is considered Fact data.
The columns ISO3, Date, Sex and Classification are considered Reference data.
Fact data
A fact is a set of values which is different for a set of reference columns and changes over time. It is the actual result of the parameter which is measured.
Reference data
Reference data is data like the country table which isn’t a measure and normally doesn’t change.
There are various benefits to splitting out reference data into separate tables
-
The fact data could come from an outside source and only contain the ISO3 Code for example.
- By using reference data, you now know data such as the WHO Region although the source has no idea of what it is
- You can also accept country names in different languages and know which country it refers to
- It also makes drop down lists easier to create and translate
- Standardizes things like names
- Any changes to the reference data can appear to the end user if the reference data is combined with the fact data. This is the case for both new and historic data
Aggregated data
In Excel, you can do various functions on the columns like Sum, Average, Count, Maximum and Minimum. The columns with these types of data are considered Aggregated data.
Article List / Line list
This is data which can be cleaned but contains a lot of data for example case data.
Raw (untransformed)
Sometimes, it is better to load the raw data in without any checking and data cleansing because there may be limits on the source access time or the raw data needs to be cleaned by hand before being loaded into Fact tables.
What are the advantages of using reference data?
- The fact data could come from an outside source and only contain the ISO3 Code for example
- By using reference data, you now know data such as the WHO Region although the source has no idea of what it is
- You can also accept country names in different languages and know which country it refers to
- It also makes drop down lists easier to create and translate
- It can be used to standardize things like names
- Any changes to the reference data can appear to the end user if the reference data is combined with the fact data. This is the case for both new and historic data
Many-to-Many Relationships
The Problem
Imagine there is a situation where there are 3 members of a team; Chris Diakos, Chris Faulkner and Chris Tantillo.
There are 3 tasks which require them to work in pairs; Task 1, Task 2 and Task 3.
They have each been assigned 2 tasks and they always work with someone different.
Chris Diakos is working on Task 1 and Task 2 Chris Faulkner is working on Task 2 and Task 3 Chris Tantillo is working on Task 3 and Task 1
The relationship looks like this
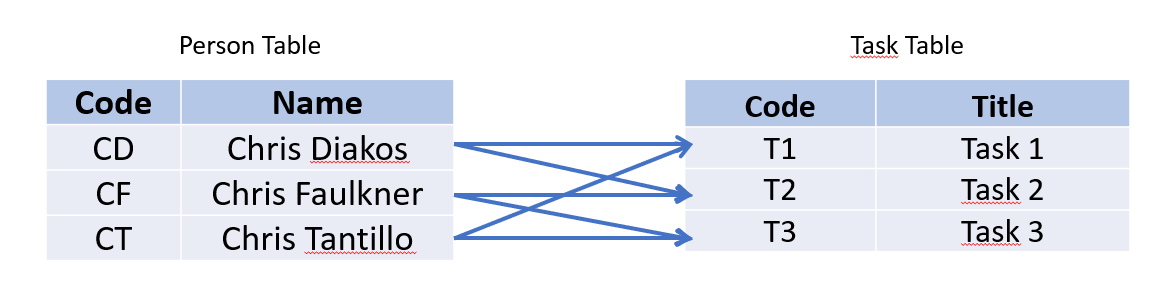
This is called a many-to-many relationship.
How do you represent this in a database?
Link Tables
As the name suggests, a Link table is used as an intermediary table between two other tables and is used to implement many-to-many relationships. It consists of 2 foreign keys pointing to the referenced records. Both of the fields are the primary key to prevent duplication.
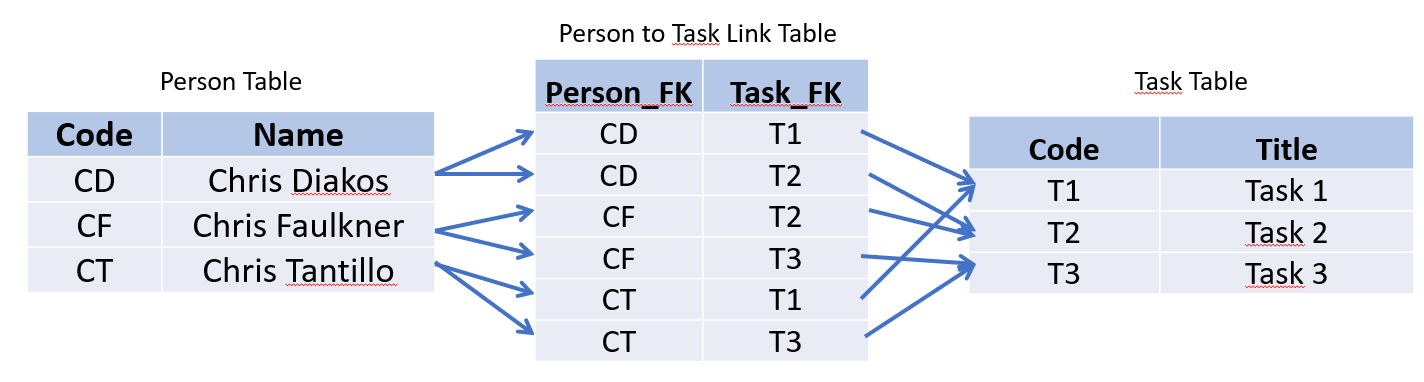
Arrows from the Person and Task tables to the Link table illustrate how the codes connect through this intermediary table, allowing each person to be associated with multiple tasks and vice versa. This structure is a classic “many-to-many” relationship model, which is commonly used in database design.