Version 4.21
New Features
Data view filtering enhancement
Filtering on the data view page has been improved. To filter or sort, click on any column header to access the new UI. Filtering options are specific to the datatype of the column being filtered.
Text columns can be filtered based on Equals, Does Not Equal, Begins With, Ends With, Contains and Does Not Contain:
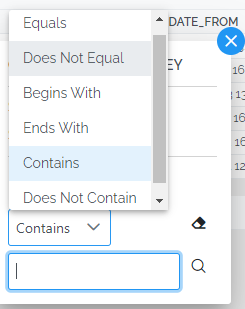
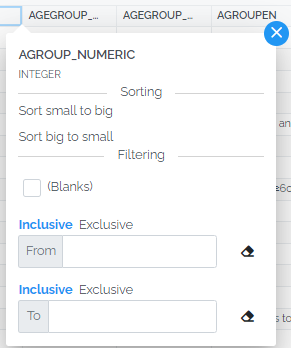
Numbers can be range filtered and you can control whether the limits are included or excluded.
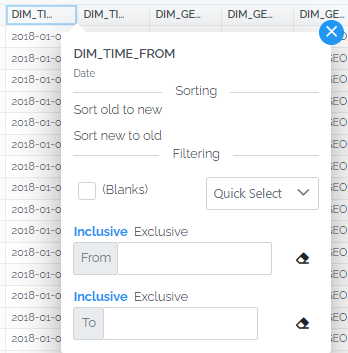
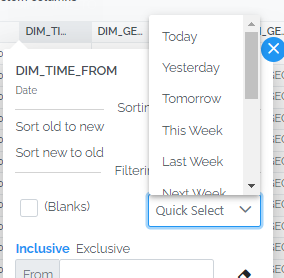
Date values are also range filtered and use a date picker to enter values. For convenience, there is a Quick Select to enter common date ranges such as Today, Yesterday, Tomorrow, This Week, Last Week, etc. Whether the filter should be inclusive or exclusive of the input dates can also be controlled.
Boolean values:
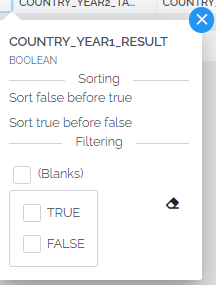
For columns of any datatype, it is always possible to include or exclude Blank values.
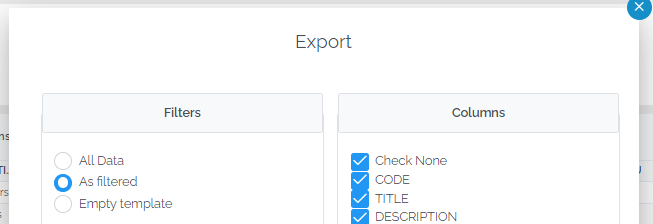
Filtering enhancements applied to data export
The data view filtering enhancement allows more complex filters to be created. These complex filters can be applied when exporting data by choosing “As filtered”.
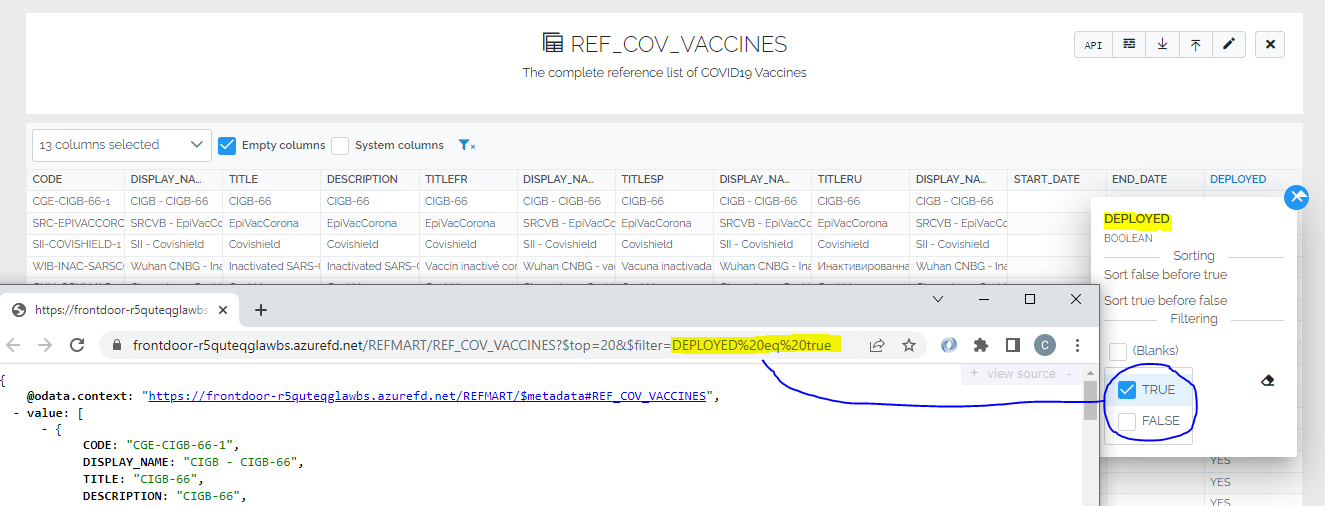
Filtering enhancements applied to the data API URL
The filters are also applied when the API button is pressed. The data view page can therefore be used as a helper to generate filtered OData API queries.
History of pipeline and custom SQL preserved
The system has always maintained a history of changes to the data model. In this version, the system begins to maintain a history of changes to pipelines and custom SQL views.
The user interface to view and retrieve the history of changes will be part of the next version (4.22). So it is unfortunately not yet possible to make use of the history but the history begins with this release.
A new version of a pipeline is created when it is published. Custom SQL views are versioned nightly, but only if they have changed.
New Test button on pipeline editor page
To support the version history of pipelines, a new Test button has been added to the pipeline editor page to allow testing of incremental versions of the pipeline without doing version control. Version control only happens when the Publish button is pressed. On the load page, only published versions of pipelines can be launched. Draft/test versions of pipelines can only be launched from the pipeline editor page.
Please use the new Test button to test your pipelines, rather than the Publish button.
If the Debug checkbox is pressed, pipelines run in debug mode. This means you can see what the data looks like at each step of the pipeline (how-to debug a pipeline)
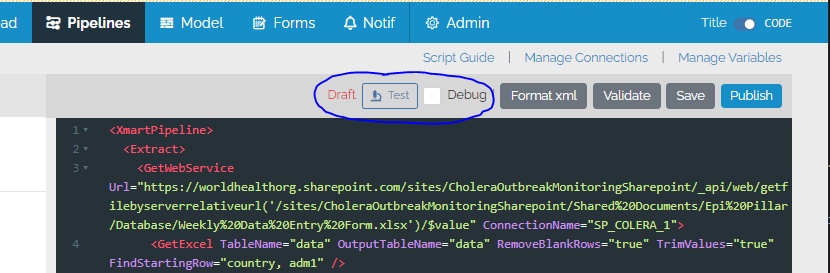
The Test button opens the loader UI with test mode indicated by a microscope icon. The Commit button is disabled.
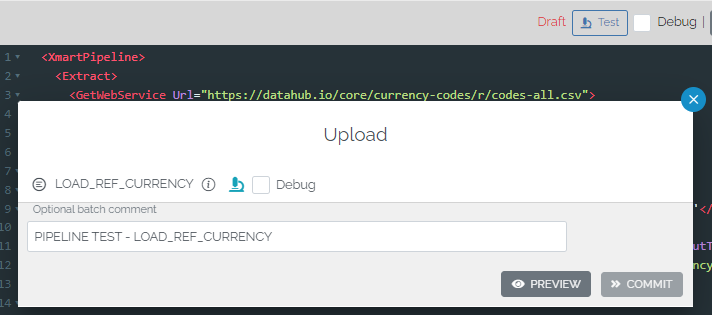
On the batch preview page, a test batch appears with the microscope icon. Test batches cannot be committed, but you can choose to simultaneously publish the pipeline and commit the result. This is reflected by a new “Publish and Commit” button.
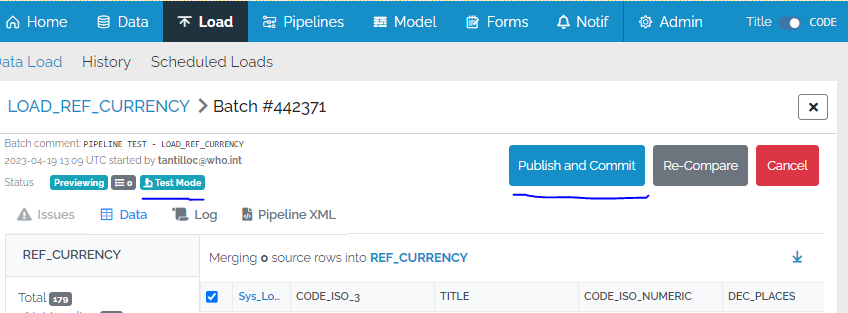
In the “Latest 25 batches” list on the load page, test batches are only visible to the person who created the test batch, so that other users do not have to see the large number of batches that may be created during testing.
Enhancements
Support for PostgreSQL
PostgreSQL databases are now supported as sources of data. The PostgreSQL database can be in the local network (the network hosting xMart) or in the cloud. The PostgreSQL connection is created on the Pipelines/Connections tab, like for SQL Server databases.

GraphQL data sources
It is now possible to consume GraphQL web services.

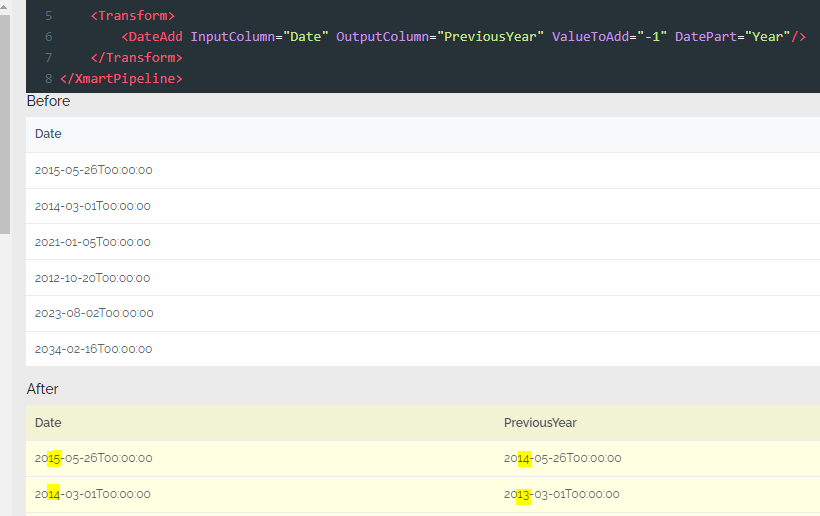
New DateAdd transform command
A new DateAdd transform command is available in pipelines to make it easier to add or subtract date/time values. It is similar to the SQL DateAdd function. For more details, see the DateAdd command documentation.
Issues sorted so that errors appear before warnings
A small enhancement, the batch issue list is now sorted so that errors (data changed, ie replacing an invalid value by null) appear before warnings (data not changed, ie, questionable values allowed to be updloaded).
Hyperlink to command in script guide from command UI
In the UI panel that opens for a pipeline command, there is now a hyperlink directly to the command reference documentation in the script guide.
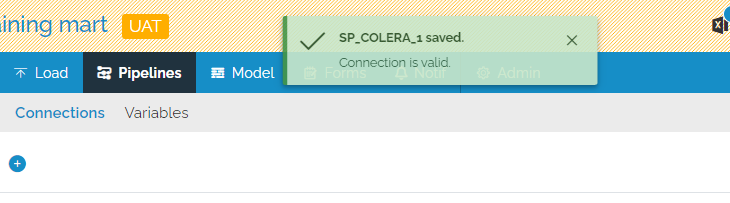
Test connection and display result
When saving a new or edited pipeline connection, the connection is tested and the result is displayed. It is not necessary to create a pipeline to test whether the connection itself is working.
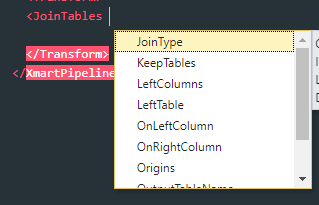
Sort Pipeline XML suggestions alphabetically
Pipeline XML suggestions are now sorted alphabetically for convenience.
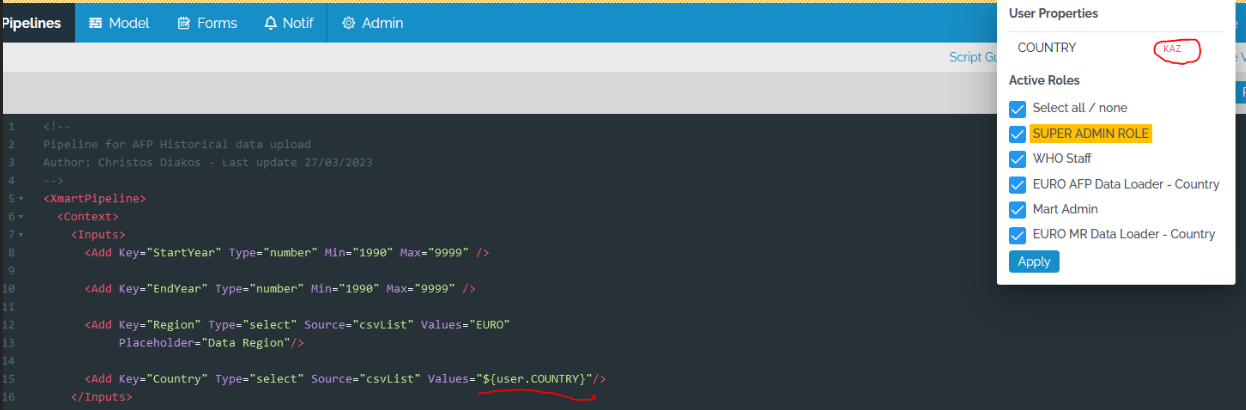
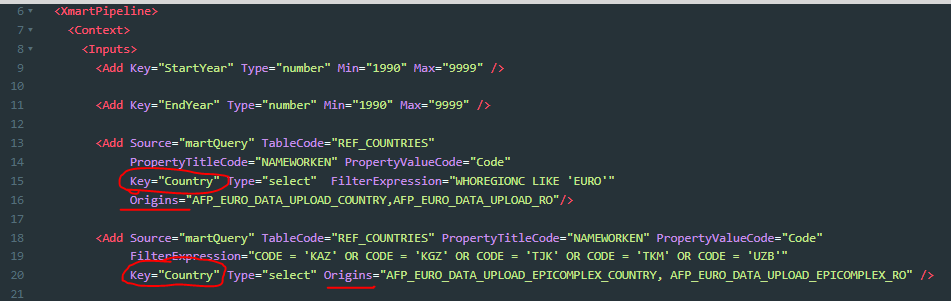
Support variables in the <Inputs> section of pipelines
System variables, user properties and mart variables can now be used in the <Inputs> section of pipelines. This means that they can be used to filter items in dropdowns shown on a form displayed when a user uploads data.
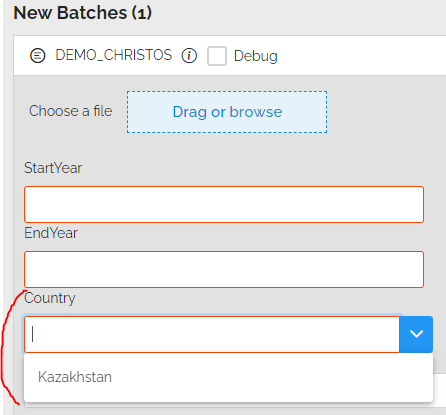
Support Origins in the <Inputs><Add> section of pipelines
It is now possible to indicate for which origins <Inputs><Add> elements apply. This supports customization of any forms displayed before uploading data.
OData API Enhancements
Improvements to the public OData API in this release:
- (security and performance) When a requested table or view does not exist, the system caches this error condition to prevent repeated trips to the database to determine that it doesn’t exist.
- (security) When the ANONYMOUS user is removed from a role, any objects going from public to private are removed from the public cache area.
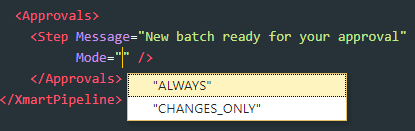
Option to send approval notification if there are no data changes
By default, during the batch approval process, if there are no data changes in the batch, no notification email is sent to the approver. It is now possible to change this behavior so that the approver receives a notificaton email even if there are no data changes. A new mode option has been added approval steps with possible values CHANGES_ONLY (default) or ALWAYS.
Other changes
- #4099 Sort on Data view not working on FK column
- #3962 fix HTML rendering of mart Description in Catalog
- #3991 Excel export: blanks cells are not really BLANK
- #4082 Load issue when TargetTable has different case
- #3979 API Cache isn’t flushed when Tables are removed from being public
- #4081 Data Edit : Add New Record then Edit New Record duplicates new Record
- #4090 Remove semi-colons in SYS_USERS_IMPORT pipeline
- #4085: Preselect dropdown item if it’s required and if there is only 1 possible value
- #4050: Unable to delete user property and should hard-delete roles instead of soft-delete
- #4041: GenerateID command produces datatyped columns rather than text
- #4027: Issues export : export issue message in the downloaded Excel
- #3980: Data catalog menu tweaks
- #3959: Should not see batches of other countries with RLS
- #4053: Loading RLS filtered records appear as unchanged rather than Out of RLS Scope
- #4016: OData “Could not wait for data being loaded,” but DB object no longer exists
- #3941: RLS - misspelled username raises exception
- #4019: RLS experience improvement
- #4056: Out of RLS scope DB data visible in batch preview
- #4033: RLS : Rename Key Column in MART_VARIABLE -> keep MartLookup brackets in SQL
- #4006: Same Error Repeated on Batch Issues Tab
- #4069: Data to Model doesn’t work with a database connection
- #4032: RLS Scope : limit to 1 filter per target table
- #4049: RLS UI tweaks
- #4074: Catalog mart description - small UI bug
- #4052: Ability to rename custom user properties
- #4078: Store data integrity issue (Missing Sys_LoadAnalysisCode for some staging rows) after changing a column to IS_REQUIRED
- #4005: Remove _Delete from Users export?
- #4094 DB Migrate: change dacpac deploy by simple SQL scripts