Version 4.22
New Features
Filter by and analyze distinct values
Excel-like column filtering by distinct values is now available when clicking any column on the data view page.
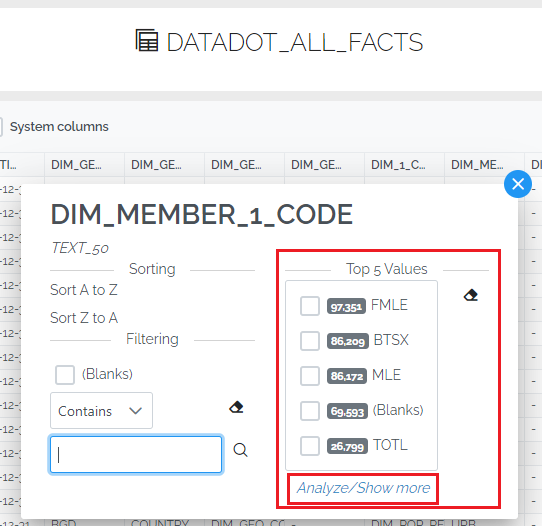
To view all of the distinct values in a column, click the “Analyze/Show more” button. This opens a new column analysis screen which additionally shows the percentage frequency of values in the column. This can be a quick way to do some data quality assurance. It is also possible to filter the data view from this screen.
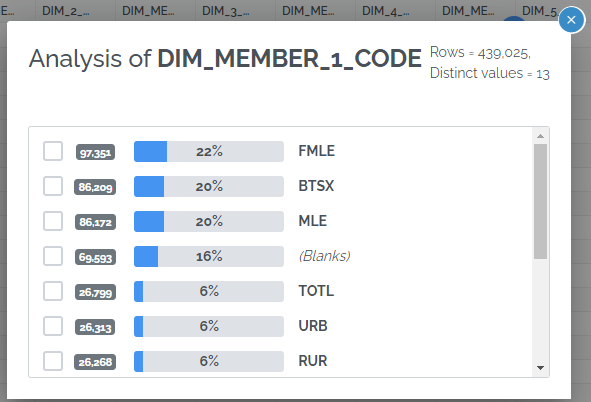
Pipeline version control
Every time a pipeline is published, a new version is created. It is now possible to view past versions of a pipeline, including who edited them and when, and graphically compare any 2 versions. Pipeline source code from a past version can be copied and pasted into the current pipeline editor.
This is available on the new History tab of the pipeline source code page.
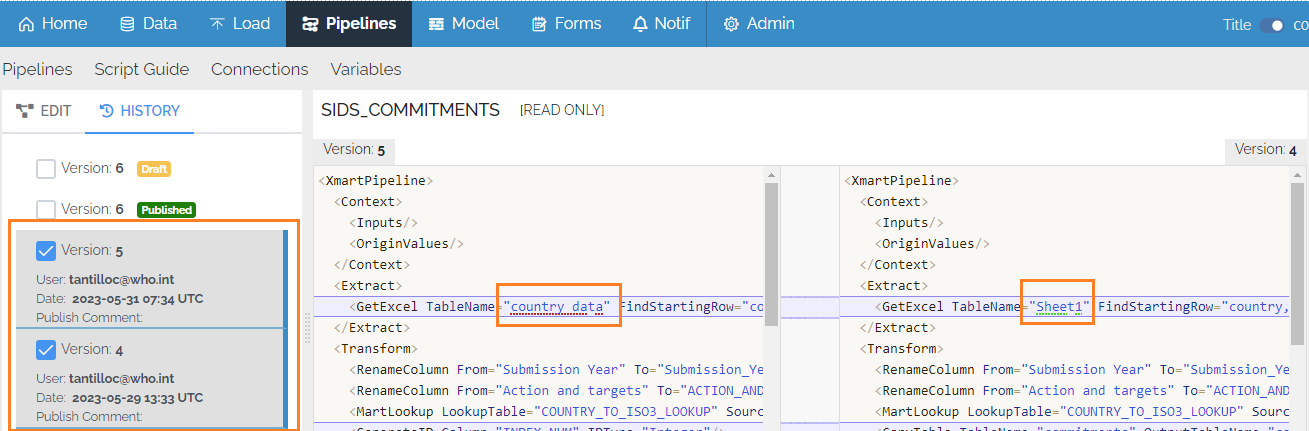
Note: It is advised to use the Test button during iterative development, which does not create versions. Only the Publish button creates a new version. The Test button performs all steps as a published pipeline, but not the final commit step - so it should be possible to fully verify a pipeline before publishing it.
For more information, please see the how-to article on pipeline history.
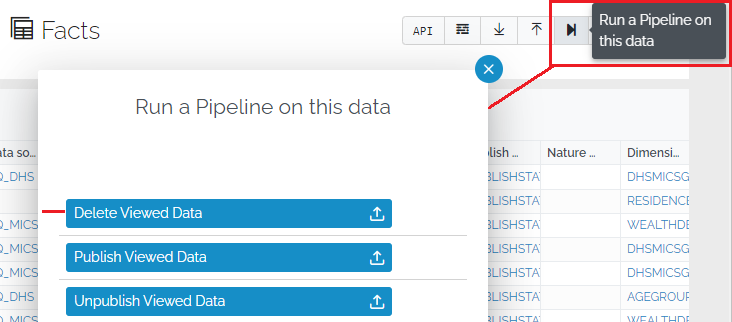
Process data view rows
This feature allows a user to launch a pipeline from a data view page which processes only the rows the user has selected/filtered on the data view page. This enables ad-hoc bulk-editing scenarios such as publishing workflow (ie changing values in a PUBLISH_STATUS column from DRAFT to PUBLISHED or moving selected rows from one table to another) or bulk deleting (ie setting _DELETE to TRUE).
This feature is explained in detail in the Process data view rows how-to article.
Process MS Word forms
A new pipeline command GetWordForm supports the extraction of data from MS Word documents containing form fields (content controls). Either a single MS word document or a zip file of word documents can be uploaded. Each word document becomes a single record in the extracted table.
This feature is explained more fully in the Consume data from MS Word Forms how-to article . Also see the GetWordForm command reference documentation.
Enhancements
#4260: Extract URL values from hyperlinks in Excel files
The underlying Url values of hyperlinks in Excel files can now be extracted by setting ExtractCellHyperlinks to true in the GetExcel command.
The hyperlink value will be appended to the cell value, separated by " | "). The default value is false. This only works for Excel 2007 and above (xlsx).
Purge public OData cache when custom SQL view is ALTERed
Previously, the public OData cache a custom SQL view was not purged when the view definition was changed at the database-level. The view change is now detected and causes the public OData cache to be refreshed automatically.
Prevent public OData requests of slow custom views from spamming the DB
Multiple requests of very slow custom views via the public OData API no longer reaches the database. Previously, it was possible for multiple requests of slow custom views to accumulate in the database, affecting overall system performance.
Memory-optimized staging tables
A system setting can activate “memory-optimized staging tables”, the ability to stage data being loaded in memory rather than on disk in the backend SQL Server database. This has been implemented as part of an ongoing effort to improve the performance of a cloud-hosted version of the system. On the Azure cloud, the setting requires the “Business Critical” service tier. In a non-cloud installation, the setting requires either an Enterprise license or a Standard license with 32 Gb of memory or more.
Other changes
- #4201: Hierarchy Lookup Produces Something went Wrong on failed Lookup
- #4250: Encrypt sensitive system information
- #4249: Using IsStructure to set Mart Variables in a Pipeline may reveal variables from other marts
- #4227: Invalidate command - optimize DataLakePathClient.Exists calls
- #4244: Test Button still shows if Pipeline published from Editor
- #4107: LowLimit parse date failure
-
#4262: Wrong data catalog tags
- #4292: Pipeline deploy TEXT_MAX / XML diff popup does not update anymore
- #4276: Check for null martCode in StartOrigin web service
- #4295: Data view filter does not work for UNICODE characters (ex: arabic characters)
- #4270: Connections : Secret Value is substituted in Connection Parameters on Save
- #4294: Column values picker: filter by more than 5 values
4.22.7
- #4320: fix Pipeline history feedback from users
- #4321: StageLookup could cause pipeline validation error
- #4323: RLS could cause some views to fail in the api
4.22.8
- #4331: improve performance of PivotColumns when pivoting on a large number of columns
- #4342: SplitCellsToRows: add a Filter attribute to only split cells that match a predicate and leave the rest of the row intact
- #4343: SplitDate: add an ImpactOnError attribute to control whether the pipeline should fail if the date cannot be split or keep processing other rows
- #4328: More pipeline XML diff quirks: only show XML_Draft diff