Tutorial 3. Model Validation
How can we apply validation rules to the data?
It is possible to define custom business rules in a pipeline. But before getting to custom business rules, you should know that the data model automatically provides some basic validation – without any extra work.
The data model will automatically enforce:
- Data types such as integers, dates, booleans, etc.
- Lengths of fields
- Required fields
- Duplicate business primary keys (as in previous tutorial)
Model validation is “strict” but has a minimum “impact”. If the model expects an integer and a non-integer value is provided, that value is not allowed to be uploaded. It is strictly enforced.
However, the impact of the issue only affects the value; it is replaced by a NULL. The record containing the invalid value is still permitted to be uploaded (unless it’s a required value too), as well as the other records in the table.
In contrast, when you define custom business rules (future tutorial), the impact is configurable. An invalid value can block a whole record or table from being uploaded. Or an issue can simply be a “warning” and have no impact at all on the data.
Let’s experience model validation by introducing some errors into our data.
First, a reminder of the data model:
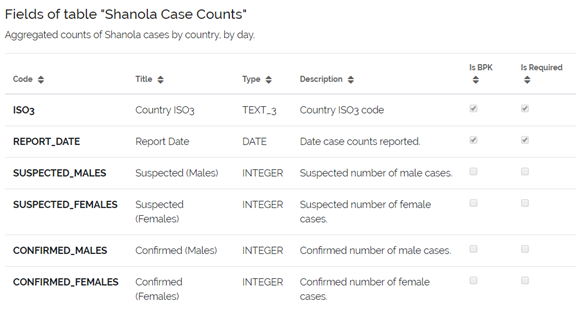
Some issues:
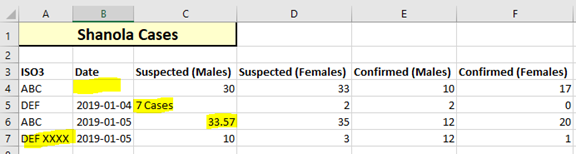
Issues Tab
Uploading and previewing this data causes the Issues tab to be displayed. Issues are classified by their impact, in this case Invalid Rows or Invalid Values.
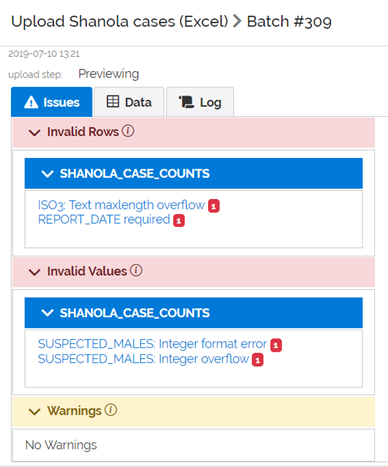
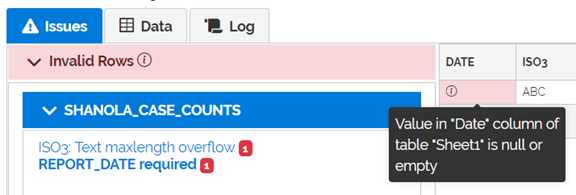
Clicking on the first issue, “ISO3: Text maxlength….” Shows where the issue occurs in the uploaded data. The field(s) containing the issue are shown in the left-most position of the table. Putting your mouse over the “i” icon reveals more detail:
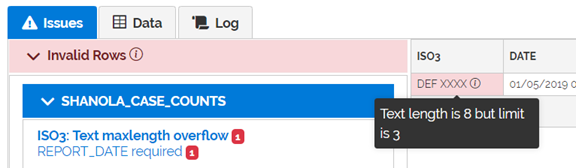
Because the ISO3 code is marked as required in the data model, the invalid value causes the entire row to be invalid.
Like-wise for the missing Date value
On the other hand, the issues with “7 cases” and “33.57” (which are not integers), are simply invalid values, because this column is not a required column. The values are replaced by NULL values only.
Data Tab
While the issues tab focuses on the issues, the Data tab focuses on what will actually be uploaded. The Data tab will not show every issue, but does provide accounting of how many rows will not be loaded due to errors.
Next to “SHANOLA_CASE_COUNTS”, there is a green and red badge, both with the number 2.
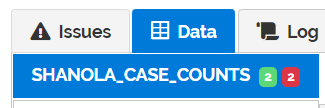
The green badge indicates how many rows will be uploaded. The red badge indicates how many rows will not be uploaded.
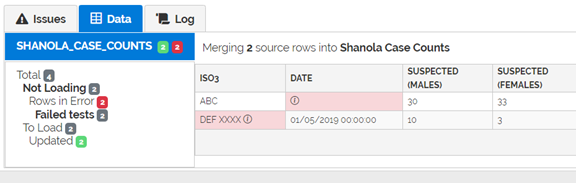
In this case the 2 “Not Loading” rows are due to “Failed tests”. Clicking on “Failed Tests” displays these rows, in a format similar to what was displayed on the Issues tab.
Clicking on “Updated” displays the data updates that will happen.
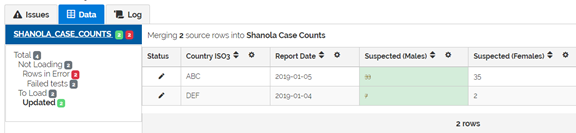
The invalid values were replaced by NULL values. The NULL values replace the pre-existing values in the database (33 and 7).