New Features
Data change notifications and table change history
You can opt to be notified at selected frequencies (immediately, daily, weekly, monthly) when one or more tables’ content changes, even if you only have data view rights on the table. This makes it possible to subscribe to changes in REFMART tables, ie, “notify me when the country list is modified”.
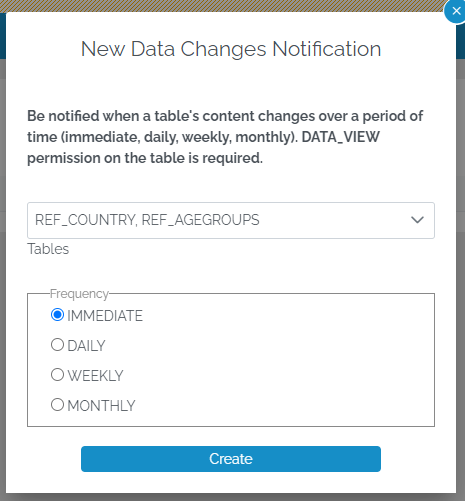
The notification email links to a new change history tab on a table’s data view page.
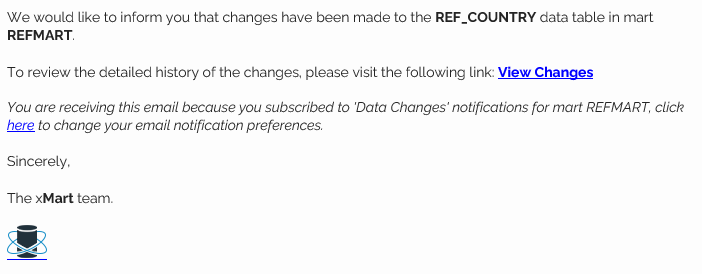
Clicking the link in the email opens a new data history page and shows the changes for the time period selected in the notification.
It is also possible to access the data history page directly without having received a notification.
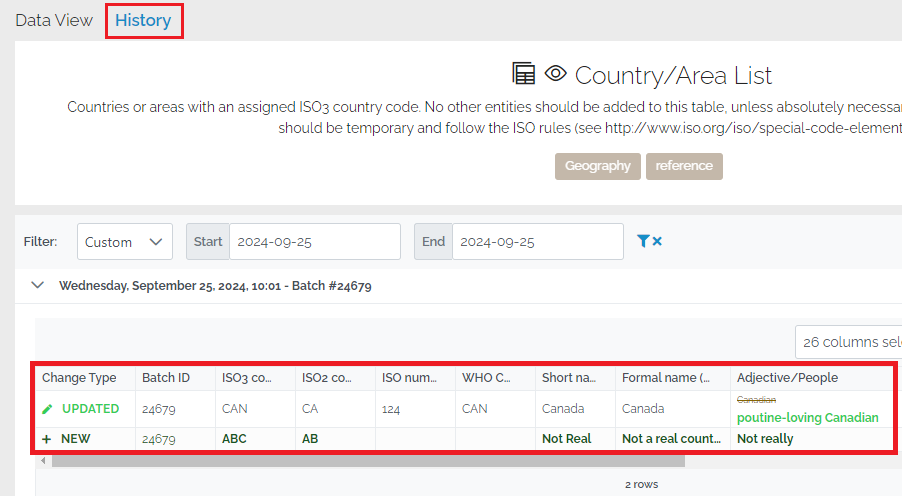
Note to pipeline editors: change history is not maintained if the REPLACE load strategy has been used.
Please refer to the data change notifications article
Data entry subforms
Custom data entry forms now support the ability to embed a “subform”. With the SubForm feature, a user may edit a table within a form. For example, a form for entering details of a linelist/case record can have a subform for entering a list of lab samples for the case.
For more information, please see the article on SubForms.
Enhancements
Data Catalog
Improved Data Catalog page performance
The performance of the top-level data catalog has been improved so it is easier to browse. The top-level catalog makes the content of all public tables and views in all marts available to xMart users.
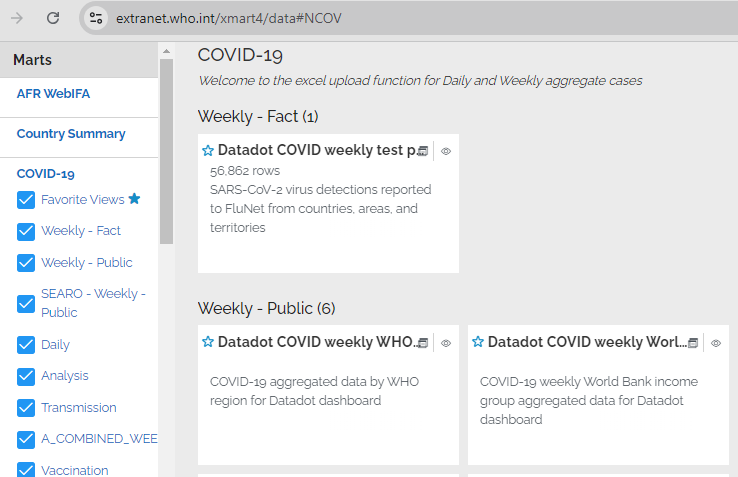
For example, WHO public COVID-related tables and views:
Data Loading
Reduced issue count for lookup issues
Large numbers of data loading errors exceeding the error limit fails a batch. Sometimes this is caused by just a few invalid values which are repeated many times in a data source. For all lookup commands (TableLookup, MartLookup, DbLookup, HierarcyLookup), the system will now only count a repeating invalid value as a single issue rather than as a list of issues. This should reduce the error count and allow more data loads to complete rather than be failed.
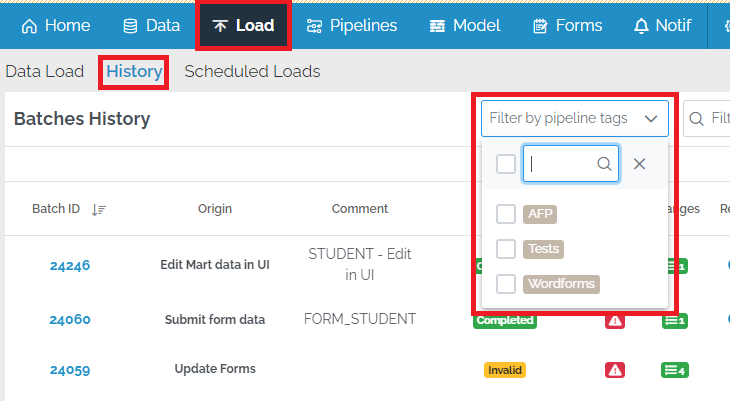
Filter by pipeline tag in batch history
It is now possible to filter batches on the Load/History page by pipeline tags.
Data Model
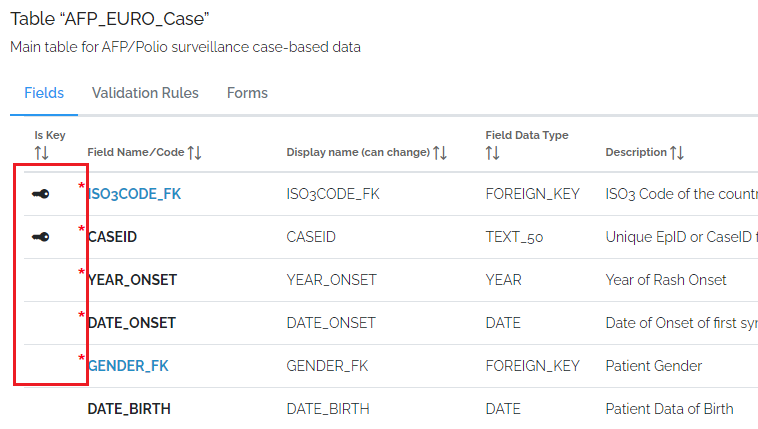
Model page UI enhancements
To emphasize the business primary keys (BPKs), required fields and row title of a table, they have been moved to the leftmost column and represented by standard icons.
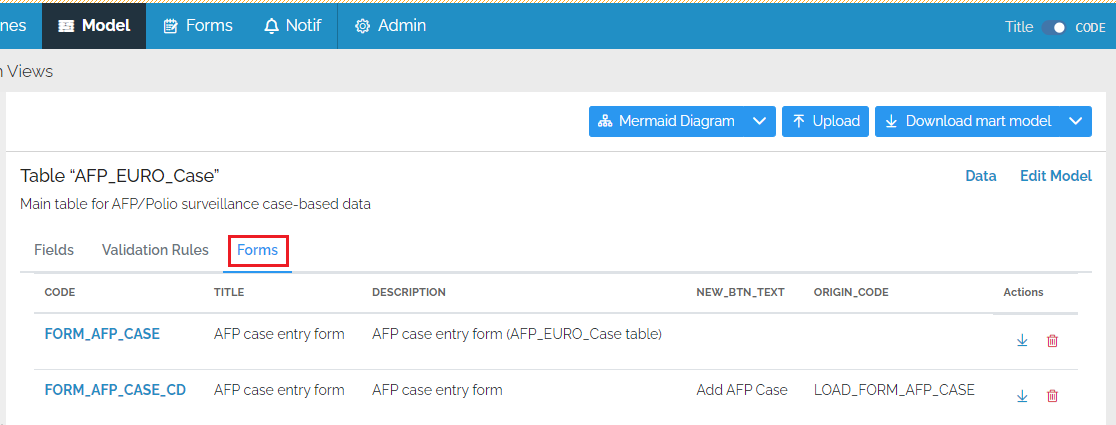
List of forms attached to table
For convenience, the custom data entry forms attached to a table are now listed on the table’s model page. Links are available to open the form and to download the form definition.
New table-level TestRow validation rule
The TestRow validation rule, which was always available as a pipeline-level validation rule, is now available as a table-level validation rule. This means it can be defined once and attached to a table and is enforced regardless of how data enters a table, including displaying an error message in data entry forms.
In addition, TestRow has been enhanced to support a new mode where a filter expression can be defined. Please see the TestRow reference documentation
OData API
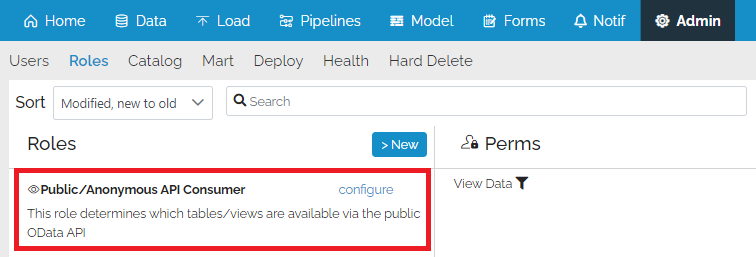
New way to make objects public via API
There is a new way to make tables and views public via OData API which is easier and safer. It replaces the “Add Anonymous User” button.
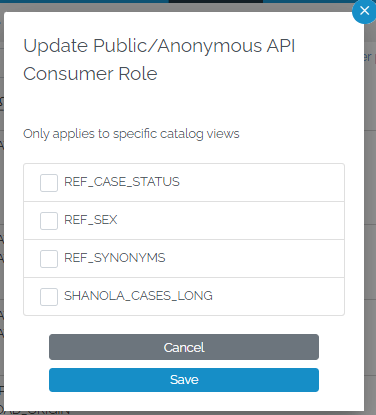
To make a table/view public (or to make it private again) click configure on the role called “Public/Anonymous API Consumer”, and select or deselect objects as needed.
This role is a new system-managed role which is automatically available in every mart.
A few notes:
- This replaces the “Add Anonymous User” button.
- This should reduce the number of tables and views which are accidentally publicly exposed.
- The role has an eyeball icon by it. This is the same icon used on Data pages to flag public tables and views.
- The only configuration that is possible is selection of tables and views. It is not possible to add users to this role. It is not possible to add or remove permissions from this role.
- During the upgrade of 4.25, the public/anonymous user was removed from all user-defined roles and any public objects were transferred to the new system role.
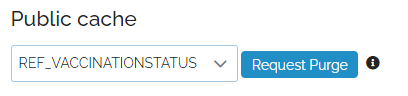
Manual purge of public API now immediate
Requesting a public cache purge now has a more immediate effect. Previously it was necessary to wait up to 60 minutes for the public cache to be purged. The wait time has been reduced to just a few minutes to purge all ~190 edge servers around the world. Access the public cache purge feature via the Admin/Mart page.
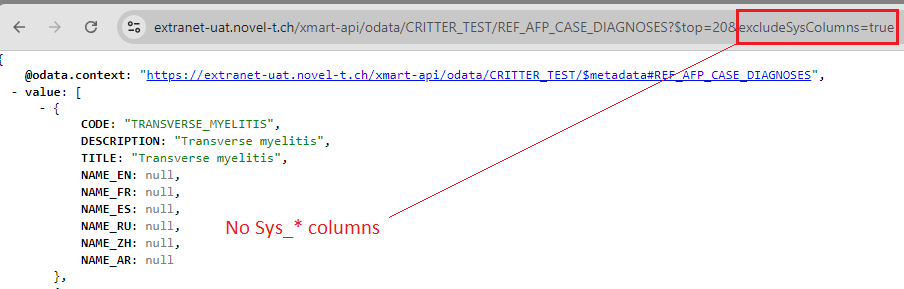
Option to exclude Sys columns in OData response
A url parameter named “excludeSysColumns” can now be used to exclude system columns in the OData response. This applies to both public and private API endpoints. Set it to “true” or “false” (default is false).
Note that this is not a standard OData parameter and therefore does not have a “$” prefix.
Pipelines
Download debug tables
When debugging a pipeline, it is now possible to download the debug tables at any debuggable step of the pipeline.
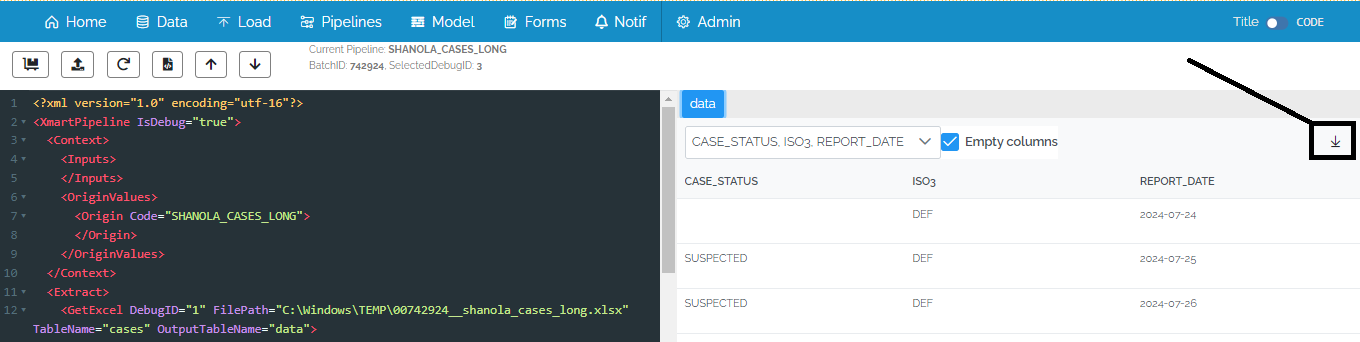
SQL formatting preserved when formatting a pipeline
When a pipeline is formatted, any SQL in the pipeline is left alone, preserving any SQL formatting. Previously, the SQL formatting would become messed up when the pipeline was formatted.
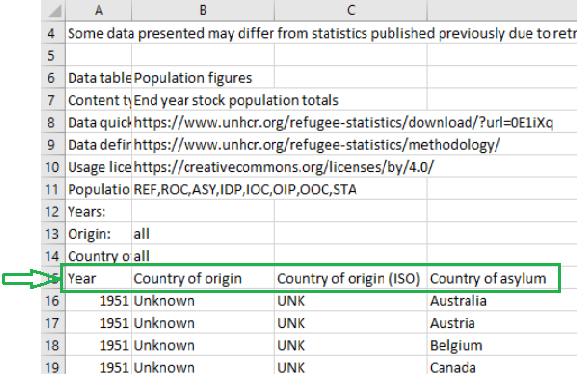
GetText supports FindStartingRow
The GetText command now supports FindStartingRow, just like GetExcel.FindStartingRow, to make it easier to extract data tables from csv or tsv files containing extra information at the top, such as this:
Option to not include Sys columns on GetMart
An option is now available on the GetMart command to exclude system columns (default is false).

TOP supported in GetMart
To faciliate pipeline testing when the GetMart command is used, a new Top property is supported to limit the number of rows retrieved.
Retrieve just 10 rows:

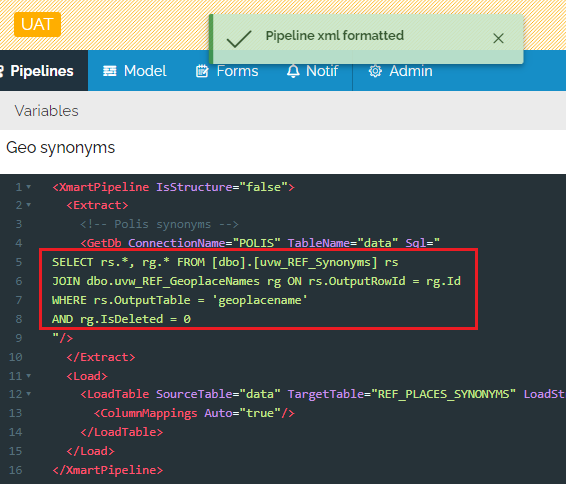
Extract data from Snowflake DBs
It is possible to extract data from Snowflake. The Snowflake database API has been implemented, not the Snowflake web API. To connect to a Snowflake database, create a new SQL connection of type “Snowflake” under SQL Connections on the connections page.

Then use the GetDB command normally to get data from the remote Snowflake database.

GetZip: Output 1 table per file
GetZip can be used to output 1 table per file in the zip. In other words, GetZip now supports 2 modes of extraction data from zip files:
In the first mode, data from all files in the zip are extracted as a single pipeline table. This is useful when all the files in the zip are structurally the same, such as a zip file of Word documents containing forms, to be imported into a single target table.
In the second mode, data from each file in the zip is extracted into individual pipeline tables (one table per file). This is useful when files in the zip are structurally different, such as a zip file of different csv files, to be imported into multiple target tables.
To use the first mode, use a fixed OutputTableName for the inner command (ex: GetText OutputTableName=”data”)
To use the second mode, use a dynamic table name with “$1” to match the capture group (the pattern in the parentheses) in the FileNameToExtractPattern expression: (ex GetZip FileNameToExtractPattern=”(\w)+\data.csv” > <GetText OutputTableName=”table_$1”)
For more details, see the GetZip documentation
Load.Auto attribute
A new capability has been added to the Load command, to perform automatic mapping at the table-level. Automatic column mapping has been available for a long time; the new capability performs automatic table mapping by automatically generating the LoadTable sections.
One LoadTable section will be created for every in-memory pipeline table whose name matches a target table in the database.
This is a useful command because with a simple pipeline such as this ….
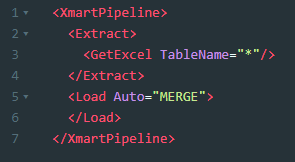
…. a variable number of Excel worksheets can be loaded and automatically mapped to target tables, provided the names of the Excel worksheets match the codes of the target tables.
The value of the Auto attribute can be set to “Off” to turn off auto mapping. Otherwise it should be set to the Load Strategy to be used for each LoadTable section (MERGE, REPLACE, APPEND).
When Load.Auto is set, you can still explicitly create LoadTable sections, so you can have a mix of auto-mapped and expclicitly mapped tables.
This feature is currently used to support data entry subforms and will also support a planned future ability to export, edit and import a variable number of mart tables in a single zip file.
Improved HierarchyLookup for subnational geography
Identification of sub-national geographic entities has been improved in cases where an indirect synonym match and a direct reference table match contradict each other. The system now uses the direct reference table match rather than the indirect synonym match. This increases the percentage of freetext subnational place names which can be converted to recognized geographic identities.
Other changes
4.25.0 - 4.25.2
- #4766 User with PIPELINE_MANAGE perm can create origins but does not see them
- #4968 Subforms feedback
- #4963 Data changes notification feedback
- #4964 Data history load analysis type is NEW but should be REPLACE
- #4911 Dynamically determine login redirectURL in OData API
- #5006 Issue in TestRow example
- #5010 Data edit in UI Forms. The text doesn’t change from Add New Record if a record has been found
- #5012 Alter launch pipeline title text
- #5014 Data Edit Grid - New records not appearing
- #4766 User with PIPELINE_MANAGE perm can create origins but does not see them
- #4785 Role configure - entity truncation in the UI (
V_SEC_ROLE_PERMS.FiltersValues5000 chars) - #4797 Do not throw an error in lookup commands if either source or lookup tables have no rows
- #4782 Display column where issue is not linked to stage table (eg: global Transform)
- #4215 Deal with large spikes in OData queries that pass frontdoor (queryStrip?)
- #4806 Reprocess batch in Test Mode uses published pipeline
- #4807 Filtered data doesn’t show if you are not on the first page of the Data View
- #4829 FormatDate: InputFormat=null does not seem to handle the time part of dates (extracted time is always 00:00:00 or 12AM)
- #4840 Data view Click on Foreign Key doesn’t go only to the record referred to
- #4856 Improve contrast/readability of issue filter buttons
- #4857 Why 2 identical issue filter buttons? -> selected issue row not refreshed after tag change
- #4864 Display parameter substituted label for validation rule
- #2885 SQL view row counting impact improvements
- #4895 No ability to add publish comment when testing and publishing
- #4902 Error on pipeline testing Load Auto=”MERGE” when mismatched Source and Target table
- #4950 {0} should be within bounds
- #4951 Validate use of mart variables in model validation rules
- #4957 Make the gridview edit box the full width of the cell.
- #4974 Hard delete tables should also list extra tables -> rollback SYS_MODEL_UPDATE changes when it fails
4.24.1 - 4.24.18
- #4691 fix pipeline decoding of non ascii characters
- #4680 restored web.config with large upload limits support
- #4700 create mart fix + hangfire graceful shutdown
- #4702: Pipeline cannot be renamed anymore after base64 change
- #4655: Custom view history - version created without any change
- #4667: Unable to view change history of unregistered view
- #4671: Remove History link on Custom Views page
- #4699: Schema Changes Upload “TEXT_MAX not allowed as BPK” message shown for all TEXT_MAX fields even non BPK -> .BooleanValue helper
- #4693: SqlDatetime overflow - critical error for some invalid date in MS access input file
- #4688: GenerateHash tweak - Algo as enumeration
- #4685: UAT/PROD - Better manage shared machineKeys
- #4706: Admin Catalog UX - view row not clickable and categories checkboxes not loaded
- #4722: Name of OData csv file download is strange
- #4723: odata/PBPORTAL/EXT_AMRO_ACT_AWARD_BUDGET/$count returns 500
- #4734: File row count - “was set to 100_000 and now only accepting 1_000”
- #4730: DBMigrate tweaks
- #4728: xmart home - fetching too much data (perms, marts info)
- #4737: Forms: Error if value in FK_FIELD_TO_SORT_BY
- #4739: Power query Odata.Feed - Unexpected error: Specified method is not supported
- #4679: Websockets blocked by WHO Proxy after upgrade
- #4743: Unable to download file with russian chars from batch.
- #4637: sp_refreshview impacted views after model changes
- #4748: POSTed file from connected app has 0 bytes
- #4749: BGCallback_DoBatchIssueExportWorkAsync failure on PROD
- #4754: Batches History column headers not aligned
- #4681: PROD batch - Error Message: Incorrect syntax near ‘)’.
- #4760: Updated FormatDateCommand reference documentation.
- #4756: Unable to parse date time with timezone (actually hour on 1 digit)
- #4768: Internal Error: Unable to complete pivot column command
- #4770: Pipeline - cannot validate a pipeline with non Latin1 char (charCode > 255)
- #4681: handle “Incorrect syntax” error if no column can be mapped
- #4768: PivotColumns - handle null strings in HeaderColumn
- #4770: pipeline unicode char
- #4795: View History job failure due to new mart ending with c
- #4792: Table Level Validation Rule is not translated correctly into Pipeline - TestValueInRange CompareType=”Auto” fails validation
- #4787: Forms validation rules, “${Now.DateUtc}” has not been parsed as date value
- #4798 load views in multiple requests
- #4809: GetJsonApi nows add extra columns for every row
- #4802 api v4.24.13 : DBLogger not registered properly at Startup
- #4799 re-enable button after mart creation error
- #4814: replace xmart-api/odata segments in the FD url for master
- #4814: use CustomUrlHelper to correct place
- #4820: Error uploading a excel file “String ‘1’ was not recognized as a valid Boolean.”
- #4814: Incorrect metadata link in prod and uat
- #4808: Email notification issue in PROD
- #4774 Better HIDE_EXPRESSION and LookupInterval.SkipIntervalInIssues
- #4867 Fix validation column mapping on HighLimitColumnName
- #4879: Model template rules includes table’s RowTitle instead of code (potential duplicate prefix)
- #4875: MartLookup times out
- #4871: Tweaks to hierarchylookup issue message
- #4861: Error: GetWebService “TLS alert: ‘HandshakeFailure’”
- #4684: Can’t use POST for public & private API (regression)
- #4680: Migrate legacy web.config to ASP NET Core