To use MERGE, we first define the “business primary key fields” of our data.
Business primary key fields (BPKs) are 1 or more fields which together uniquely identify each row. When the system can uniquely identify rows, it is able to match rows in current upload with previously loaded rows. It also prevents rows with the same primary keys values from being uploaded.
Define primary keys
To define primary keys, we open our data model template file. Alternatively, you can obtain the latest version of the data model file on the Model page by clicking “Download mart model”:
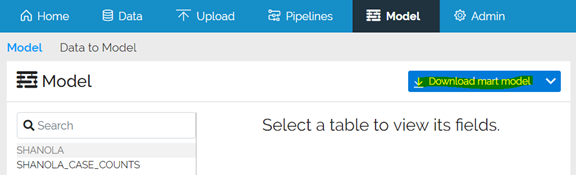
For the Shanola Case Counts dataset, the ISO3 and Date columns together uniquely identify each row. Let’s mark them as the primary keys. At the same time, let’s mark them as mandatory. Primary keys do not have to be marked as mandatory, but for this dataset it makes sense, because the country ISO3 and date values really are required:
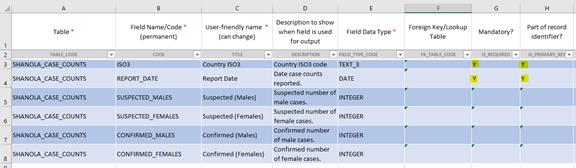
Refresh the data model by repeating the process in Tutorial 1. The changes to the model are highlighted:
Commit the changes. Then let’s chage the load strategy from REPLACE to MERGE.
Change load strategy to MERGE
In the LoadTable element, we change the word REPLACE to MERGE:
<LoadTable SourceTable="Sheet1" TargetTable="SHANOLA_CASE_COUNTS" LoadStrategy="MERGE">
That’s all that is needed. If you did not define primary key values, the pipeline validation would fail.
Upload data again
Let’s upload the data again. First, let’s load the corrected file. Then let’s try loading the original incorrect one.
The corrected file
This the file which we just uploaded in the previous tutorial:
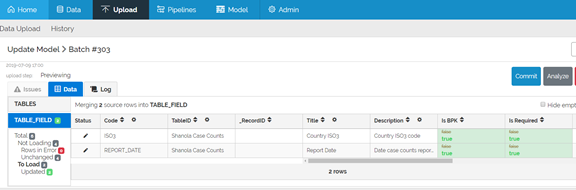
When we load the same exact corrected file again, the system now reports 4 Unchanged rows. Therefore, there are 0 rows To Load. The system will not make any changes.
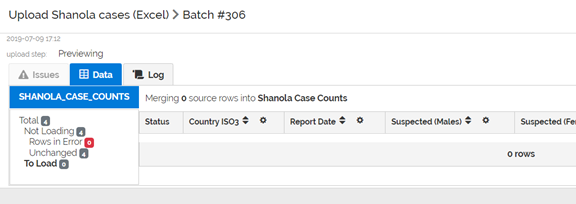
If you click on the Unchanged menu item, you can see the unchanged data (which is not loaded)
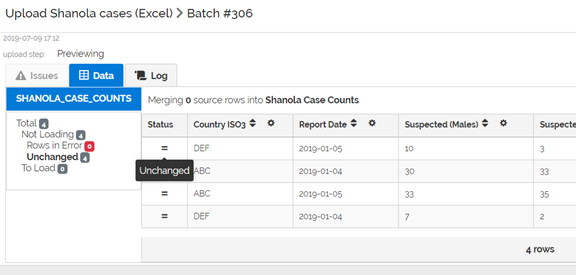
The system is now matching rows in the uploaded data with rows in previously loaded data and determining whether any values in the rows have changed.
Another benefit of the MERGE strategy is that the system permanently archives all changes. This is not the case with REPLACE. With REPLACE, a temporary backup of the previous is kept for a period of time and then deleted. There is no permanent archive of changes.
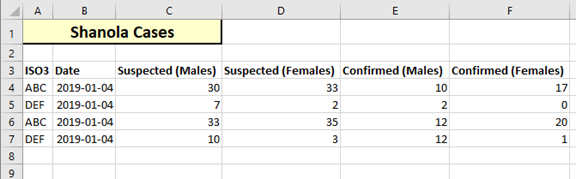
The incorrect file
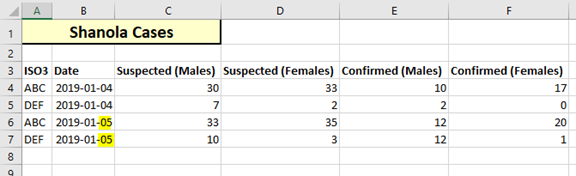
What happens if we try to load the original, incorrect file? As a reminder, this is the file with 4 identical date values.
When this file is loaded using MERGE, the Issues tab is displayed. The system has identified 4 duplicates. Click on the word Duplicates to see them.
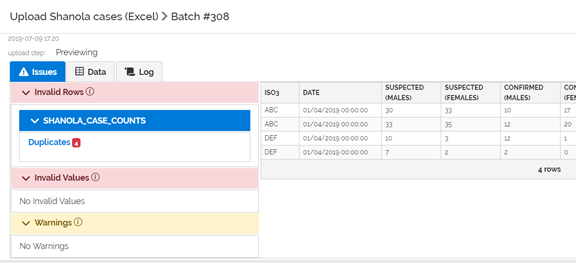
Because we marked the ISO3 and Date fields as uniquely identifying a row, the system does not allow these 4 rows to enter the system, because there are now two duplicate rows with ‘ABC’ and ‘2019-04-01’ and two duplicate rows with ‘DEF’ and ‘2019-04-01’.
If you switch to the Data tab, you will see a menu item called Duplicates under Rows in Error. There are 0 rows to load (because all are duplicate rows).
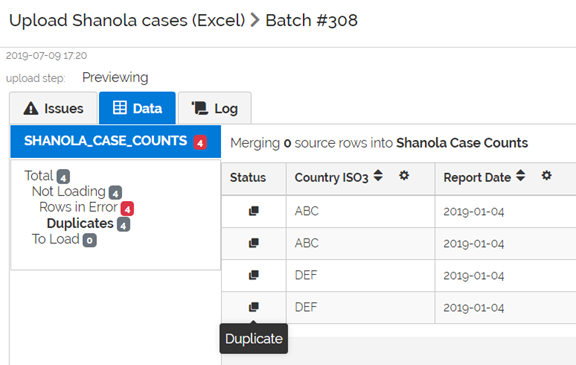
By defining business primary key fields and using the MERGE strategy, the system helps us identify duplicate rows.